
Ứng dụng lấy Text từ hình ảnh đơn giản sử dụng Tesseract OCR bằng Java
Tuy cái này cũ lắm rồi, công nghệ cũng chẳng có gì mời, nhưng đôi khi vẫn có thể sử dụng cho những bài toán đơn giản ví dụ tác thông tin chứng mình thư, số công tơ điện, công tơ ước ….
Hãy cùng xem một ví dụ rất đơn giản về OCR được triển khai trong Java.
Bước 1: Download tessdata [eng.traineddata]
Bước 2: Lấy hình ảnh muốn bóc tách lấy chữ
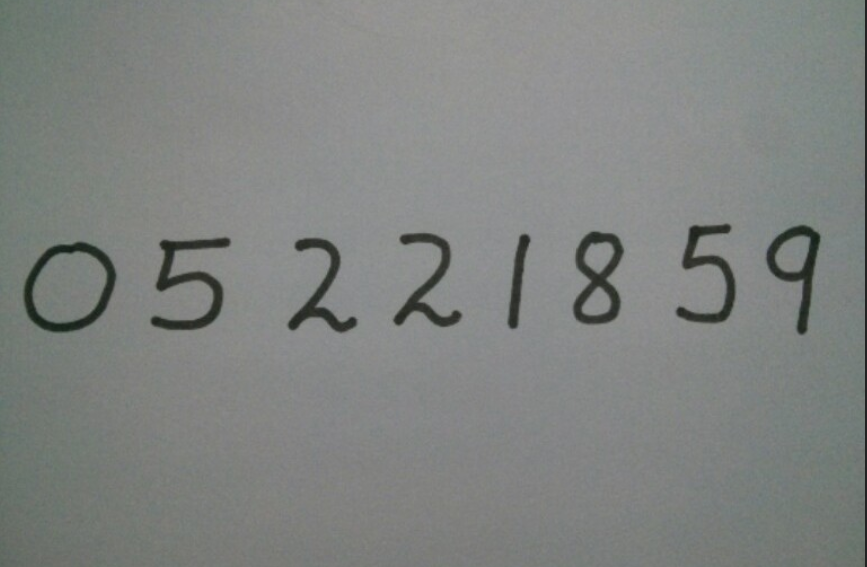
Bước 3: Thêm dependency vào tệp pom.xml
<dependency>
<groupId>net.sourceforge.tess4j</groupId>
<artifactId>tess4j</artifactId>
<version>3.2.1</version>
</dependency>
GitHub Source: https://github.com/nguyenq/tess4j
Bước 4: Viết đoạn mã thực hiện OCR
package tess.test.TestTesseract;
import java.io.File;
import net.sourceforge.tess4j.Tesseract;
import net.sourceforge.tess4j.TesseractException;
public class Test {
public static void main(String []args) {
Tesseract tesseract = new Tesseract();
try {
tesseract.setDatapath("D:/khanhlv/tessdata");
String text = tesseract.doOCR(new File("D:/khanhlv/Images/digit.jpg"));
System.out.print(text);
} catch (TesseractException e) {
e.printStackTrace();
}
}
}
Bước 5: Chạy thôi nào
P/S: Bạn có thể dùng Google Vision API để bóc tách, dữ liệu sẽ trả về dạng REST JSON.